
Системы речевого общения
В системах ЕЯ-общения обычно предполагается, что в качестве средства общения используется текст или письменная речь. Поэтому в системах ЕЯ-общения под текстом понимается орфографический текст (как пишется), а в системах речевого общения (СРО) используется фонемный текст (как слышится). В СРО решаются задачи преобразования «текст - речевой сигнал» (синтезатор речи) и «речевой сигнал - текст» (анализатор речи). Синтез речи - это возможность обработки текстовой или числовой информации, согласно установленным правилам произношения для конкретного языка, и преобразование ее в синтезированный голос, по восприятию близкий к человеческому. Анализ речи - это распознавание отдельных слов или слитной человеческой речи, с последующим ее преобразованием в текст либо последовательность команд.
На рис. 5.3 показано общее место анализатора и синтезатора речевых сообщений в потоке информации.
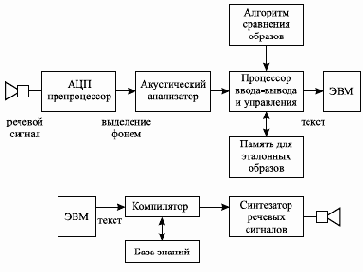
Рис. 5.3. Анализатор и синтезатор речевых сообщений в потоке информации
Первые СРО стали появляться в конце 70-х годов. Это было связано со следующими преимуществами СРО:
- удобство, простота и естественность процедуры общения, требующей минимума специальной подготовки;
- возможность использования для связи с ЭВМ обычных телефонных аппаратов и телефонных сетей;
- устранение ручных манипуляций с одновременным увеличением скорости ввода информации (в 3--5 раз быстрее по сравнению с клавиатурным вводом) и разгрузка зрения при получении информации. Первое и второе преимущество с наибольшим эффектом стали находить применение в автоматизированных системах управления (АСУ). Третье свойство весьма эффективно может применяться при создании систем оперативного человеко-машинного управления сложными объектами (управление движением, энергетическими установками и т.д.).
Обучающие системы, синхронный перевод с одного языка на другой, говорящие книжки, говорящие компьютеры для слепых, управление голосом инвалидными колясками, приборы для генерации и восприятия речи глухонемыми - вот лишь неполный перечень применения СРО.
В основе СРО лежит работа с фонемами. Фонема - это минимальная смысловая единица речи. В русском языке 42 фонемы: 6 гласных и 36 согласных. В английском языке 20 гласных (из них 5 дифтонгов) и 24 согласных, во французском - 16 гласных и 20 согласных.
Акустические характеристики фонем обусловлены местом и способом их образования. По месту образования фонемы делятся на губные (п, б, ф, в, у, м), зубные и межзубные (д, о), альвеолярные (с, з, р, а), заальвеолярные (ш, ж, щ, э), небные (к, г, х, и, ы) и фарингальные (гортанный, например, английское h ). По способу образования фонемы делятся на взрывные (п, б, д), аффрикаты (ц, и), щелевые (ф, с, х, в, з, ш, ж,…), дрожащие (р), носовые (м, н), боковые (л), плавные (й), гласные (у, о, а, э, и, ы).
В потоке речи характеристики фонем меняются, что приводит к появлению у них оттенков - аллофонов , например, огубление согласных перед гласными, а также это обусловлено положением фонемы по отношению к ударному слогу, концу и началу слова и т.д.
Интонация и ударение определяют направленность высказывания, логический смысл, выделение главного и общего (рема и тема), вычленение семантически связанных отрезков речи. Интонация и ударение определяют просодию речи с помощью следующих акустических средств:
- мелодика - изменение частоты основного тона голоса;
- ритмика - текущее изменение длительности звуков и пауз;
- энергетика - текущее изменение интенсивности звука.
Акустические характеристики фонем. Речевой аппарат человека в виде ротового и носового параллельных каналов образует единую акустическую систему, возбуждаемую периодическими колебаниями голосовых связок либо турбулентным шумом. Распространение акустических волн в такой системе описывается уравнением Вебстера
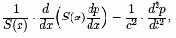
где S(x) - функция площади сечения голосового тракта вдоль оси x распространения волн; p - давление; c - скорость звука; t - время.
Анализ этого уравнения приводит к передаточным функциям по амплитуде и по частоте (некоторые из них представлены на рис. 5.4).
Речевой сигнал может быть описан как периодическое колебание y(t), создаваемое движением голосовых связок со спектром:
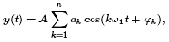
где A - среднеквадратичное значение амплитуд спектральных составляющих, ak - нормированные амплитуды k-х гармоник, ?1 - частота первой гармоники,

Для разных компонент речевого сигнала (интонация, тембр, громкость, тон, темп) используются разные виды модуляции - амплитудная, частотная, фазовая.
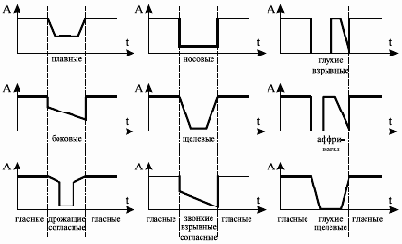
Рис. 5.4. Передаточные функции по амплитуде
Исходя из вышеизложенного, требования к анализатору СРО могут быть сформулированы следующим образом.
- При анализе заданного элемента информационной структуры осуществляется демодуляция (детектирование) речевого сигнала по каждому виду модуляции, посредством которой ведется его передача. Таким образом, на входе приемного устройства «речевой» системы связи должны быть: демодулятор длительности, амплитудный демодулятор, частотный демодулятор, демодулятор типа переносчика, демодулятор формы спектров.
- Результат детектирования по каждому виду модуляции должен быть инвариантен относительно остальных видов модуляции. Возможным методом достижения такого рода инвариантности является осуществление предварительной нормализации речевого сигнала.
- Если с помощью данного вида модуляции осуществляется передача других элементов информационной структуры, то полученный в результате демодуляции сигнал должен быть подвергнут дальнейшим операциям разделения с помощью соответствующих декодеров: декодер информации о фонемном составе, декодер информации об интонации речи, декодер информации об индивидуальности голоса, декодер информации о характеристиках среды, декодер информации о физическом и эмоциональном состоянии.
В настоящее время появляется много интересных разработок в области СРО. Одна из таких разработок - системы синтеза речи Sakrament text-to-speech engine компании «Сакрамент» (Mинск, Беларусь, http://www.sakrament.com), созданные с использованием собственных уникальных алгоритмов обработки звука, что позволило добиться высокого качества звучания синтезируемой речи и максимально приблизить компьютерную речь к человеческой.
Эти системы синтеза речи ориентированы на применение в качестве голосовых информаторов в онлайновых телефонных информационных и справочных службах, всевозможных программных приложениях, Интернет-сервисах, бытовых и промышленных приборах и т.д. Система распознавания речи Sakrament Speech Recognition Engine выделяется хорошим качеством распознавания речи, низкой себестоимостью, а также возможностью дальнейшей модификации и настройки. Основная область применения - создание программ, управляющих действиями компьютера или другого электронного устройства с помощью голосовых команд, а также при организации телефонных справочных и информационных служб.
В целом вопросом синтеза речи занимается в настоящее время большое число исследовательских групп, каждая из которых создает в конечном итоге свой программный продукт. «Клуб голосовых технологий» МГУ и фирма ПРОМТ создали «Magic Goody», компания Microsoft - Speech SDK, AT&T Германского исследовательского центра искусственного интеллекта - Verbmobil. Ведутся разработки также в Бийском технологическом институте совместно с Томским университетом систем радиоуправления и радиоэлектроники; в «Центре речевых технологий» г.С-Петербург; в компании «Истра-софт» г.Истра и других коллективах и компаниях [75], [76].